

En Feedzai, aprovechamos grandes cantidades de datos para ayudar a las empresas a combatir el fraude con eficiencia. Es parte de nuestra lucha contra los delitos financieros en constante evolución y es un trabajo en equipo. Los científicos de datos usan nuestra plataforma para desarrollar modelos de aprendizaje automático a partir de datos históricos a fin de detener a los estafadores en todo el mundo en tiempo real. Los analistas de fraudes investigan los casos más complejos y toman medidas. Los investigadores analizan las tendencias entre los estafadores y crean reglas para complementar el modelo y evitar futuros ataques.
Todas estos profesionales usan datos para alcanzar sus metas de manera exitosa. Por ejemplo, un científico de datos maneja varios terabytes de operaciones mientras que un analista investiga el historial de los clientes. Sin embargo, a pesar de las diferencias en cuanto al tamaño y al alcance de los datos que manejan, ambos necesitan comprender dichos datos.
Si me preguntan a mí, diría que la visualización es una de las mejores herramientas para hacerlo y las investigaciones lo comprueban constantemente.
Gráficos para luchar contra el fraude
Los ingenieros de visualización de datos se esfuerzan por lograr que datos complejos puedan ser interpretados mediante representaciones gráficas. Tomamos los datos, extraemos la información y codificamos sus propiedades a través de canales visuales para crear una representación gráfica.
La percepción humana, mediante el procesamiento visual inconsciente, rápidamente decodifica formas, colores, posiciones y movimientos. Como dice Colin Ware: «Las características que aparecen se encuentran programadas en la mente, no se aprenden». Por lo que podemos considerar nuestra visión como un canal de banda ancha hacia la mente.
Las visualizaciones de datos nos permiten comprender patrones e identificar con rapidez relaciones escondidas en los datos.
Esta visualización de datos rápida funciona bien en la herramienta de informe de Feedzai, Perspectivas, la cual hace que los datos (incluso mediciones de fraude en tiempo real, las reglas que se activan con más frecuencia y resúmenes de las operaciones de los analistas día a día) se puedan ver en diversos tableros. En estos tableros, se pueden diseñar gráficos fáciles de leer, por lo general junto a indicadores y mediciones.
En el mundo de la visualización de datos rápida, hay una tendencia a optar por la sencillez y los gráficos más convencionales, pero también hay espacio para la creatividad. Como dijo Amanda Cox:
«Hay una vertiente del mundo de la visualización de datos que sostiene que todo puede convertirse en un gráfico de barras. Puede que sea verdad, pero también puede que sea un mundo sin alegría».
No todas las visualizaciones son sencillas. Nuestros científicos de datos suelen crear gráficos complejos que pueden usarse para analizar distintas perspectivas en los datos (p. ej., cómo cambia la forma de distribución de una variable categórica entre las transacciones legítimas y las fraudulentas, y cómo se relaciona esto con la tasa de fraude de cada categoría). Estos tipos de gráficos no se pueden mirar por encima, no importa qué tan bueno sea su procesamiento visual inconsciente. Estos gráficos están diseñados para ser estudiados porque codifican muchos aspectos de los datos. Es una visualización de datos lenta: se invierte más tiempo y se obtienen análisis más completos y profundos.
Visualización de datos rápida y lenta
Para analizar aún más las diferencias entre la visualización de datos rápida y la lenta, consulte la publicación de Elijah Meeks «Visualización de datos: rápida y lenta».
Como ingenieros de visualización de datos en Feedzai, es fundamental que siempre sepan qué parte del espectro rápido-lento ocupa la visualización, cuánto tiempo se toman los lectores para analizar el gráfico y su dominio de los datos. No todas las situaciones requieren una visualización de datos rápida, pero no todos los usuarios quieren un gráfico interactivo elaborado. Como en la mayoría de las cosas, existe un momento y lugar adecuado para cada tipo.
Todo se relaciona
Esta publicación cuenta nuestro análisis de los diagramas de red y las características basadas en gráficos que son clave a la hora de descubrir patrones de fraude complejos y cómo nuestro descubrimiento impulsó una de las innovaciones de Feedzai: Genoma.
Empecemos con un vistazo del mundo de los pagos y el fraude.
Nos suelen decir que tengamos cuidado con nuestras contraseñas y los detalles de las tarjetas de crédito. Nos dicen que tenemos que protegerlas de hackers malintencionados y solitarios que se esconden detrás de una pantalla e intentan robarnos datos y dinero.
Si bien hay hackers que trabajan solos, los estafadores no suelen hacerlo. Por lo general, son miembros de organizaciones fraudulentas y participan en diversas actividades, entre ellas, instalar dispositivos para clonar tarjetas en cajeros automáticos y llevar a cabo ataques de phishing en línea.
Cuando los estafadores intentan convertir las tarjetas robadas en bienes que pueden volver a venderse e intentan realizar compras en línea, tienden a conectarse mediante redes privadas, dispositivos de conmutación y, luego, simulan su ubicación en distintas partes del mundo. Sin embargo, esto hace que sea más fácil que dejen un rastro sin querer. Solo hace falta que un estafador descuidado (alguien que se haya quedado levantado hasta tarde la noche anterior haciendo una maratón de muchos episodios de «Stranger Things» en Netflix) se olvide algún paso en el proceso de conmutación. Una vez que eso sucede, la organización queda expuesta y puede detenerlos. Tal vez parezca un cliché, pero todo se relaciona.
Las tablas no son un buen instrumento para las historias de fraude
A medida que reconstruimos historias de fraude mediante estas conexiones, ya sea un dispositivo compartido entre dos usuarios o alguien que utiliza diez tarjetas diferentes (las cuales también las comparte con otros usuarios), descubrimos que las tablas no son un buen instrumento para las historias de fraude.

Las cosas empezaron a verse así (consulte la imagen a continuación). Debido a eso, decidimos probar los diagramas de red y las características basadas en gráficos en la primera Zaickathon de Feedzai.


¿Le interesa leer la publicación original u otros artículos similares? Consulte el TechBlog de Feedzai, una compilación de historias sobre cómo combatimos a los villanos mediante la ciencia de datos, la IA y la ingeniería.
Zaickathon de Feedzai
Feedzai llevó a cabo su primera Zaickathon en febrero del 2018. Durante dos días, hubo pizzas, cientos de litros de café, remeras y un montón de ideas. También fue la oportunidad perfecta para probar un nuevo método de visualización.
Tomamos un conjunto de datos de transacciones de billeteras digitales con esquemas de fraude conocidos y lo visualizamos con un diagrama de red. Cada nodo representaba una entidad (un cliente, una tarjeta de crédito, una dirección de correo electrónico o un dispositivo distinto) en el conjunto de datos. Dos nodos se conectaban (con una línea que los unía) si las entidades participaron en la misma transacción. Por ejemplo:
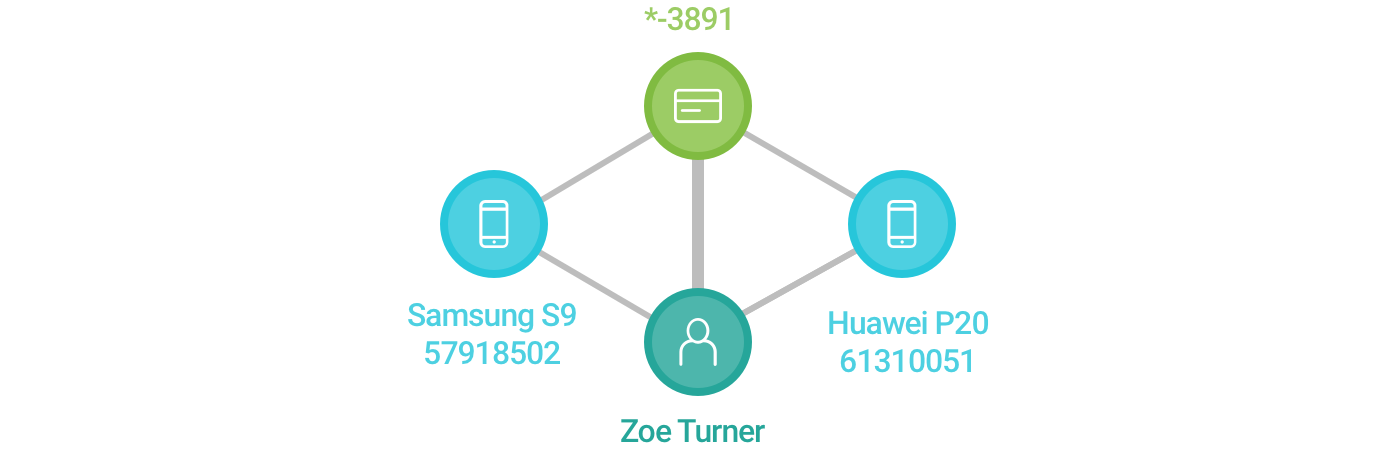
- Supongamos que somos una tienda de zapatillas en línea. Recibimos una orden de Zoe. Por los datos de transacción, sabemos que Zoe usa su teléfono inteligente, un Samsung S9, para comprar un par de zapatillas nuevo. También sabemos que pagó con su tarjeta de débito. Con estas entidades, podemos construir el gráfico que se muestra a continuación:

- Unas semanas después, recibimos más ordenes de Zoe. Paga con la misma tarjeta, pero ahora una un nuevo dispositivo Huawei. Actualizamos el gráfico y conectamos el nuevo dispositivo a Zoe con su tarjeta de débito. El grosor de la línea cambia porque es proporcional a la cantidad de transacciones en las que participan ambas entidades (nodos).
- Ahora, digamos que tenemos datos históricos pertinentes (transacciones anteriores en las que participó el nuevo dispositivo que fueron identificadas como fraude). En ese caso, querremos codificar esta información en el diagrama de forma visual. Volvamos a actualizar el gráfico.
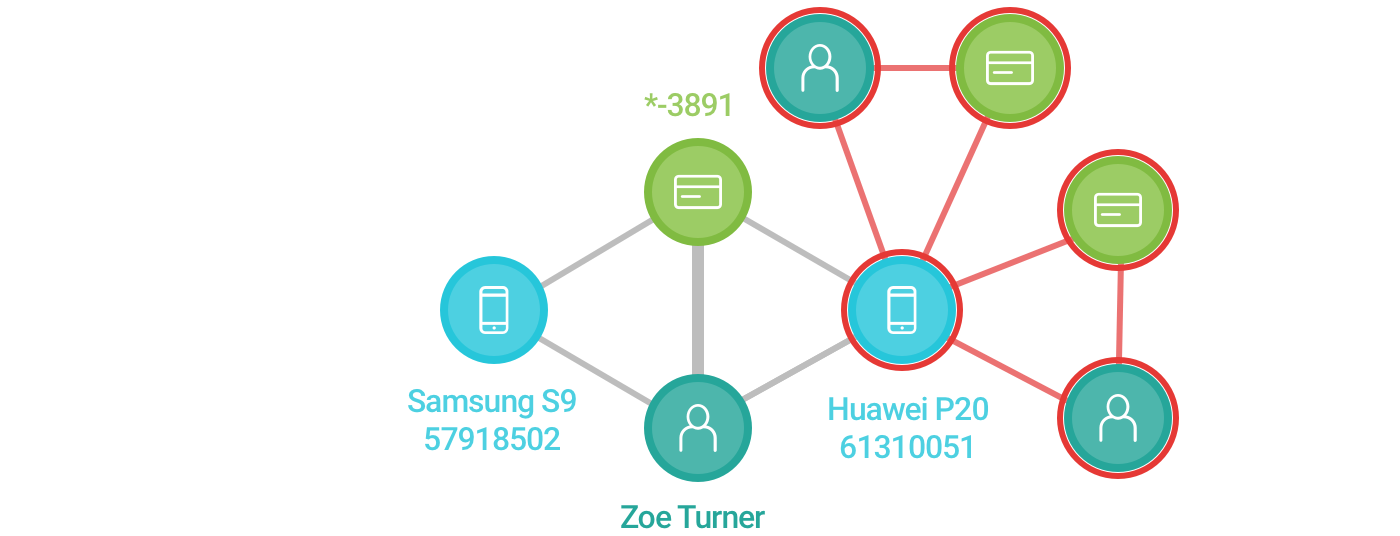
Los bordes y líneas rojos muestran qué entidades se relacionan con el fraude, según los datos históricos.
En resumen, a esta altura, hemos utilizado las siguientes codificaciones visuales:

¿El resultado? ¡Descubrimos el fraude de manera visual! En el medio de un océano de pequeños componentes conectados, salieron a la luz grandes subgráficos interrelacionados.

Mapeamos con éxito la secuencia de distintos patrones de fraude. Por primera vez, vimos la forma del fraude.
El proyecto hackathon fue un éxito y, al poco tiempo, se estableció un equipo multidisciplinario para crear un producto que surgiera de eso. Genoma se terminó convirtiendo en una herramienta de análisis visual de enlaces que aprovecha la potente tecnología de IA de Feedzai y que ofrece una manera intuitiva a los investigadores y los analistas de datos para identificar rápido patrones de delitos financieros emergentes.
Redes cada vez más grandes
Conformamos el equipo y el prototipo de dos días dio paso a una visualización gráfica escalable construida desde cero. El equipo recién estaba comenzando el proceso de desarrollo de un producto. Había notas autoadhesivas con ideas repartidas por las paredes, lluvias de ideas diarias y experimentaciones rápidas.
Queríamos tener total libertad para representar el gráfico de cualquier forma que quisiéramos: interacciones personalizadas, diseño de nodos y líneas complejo y distintas estructuras (desde la d3-force estándar a estructuras alternativas con WebCoLa). Esto significaba una cosa: teníamos que desarrollar un renderer de gráficos.
Jugamos con varias tecnologías front-end. Empezamos con SVG, pero nos dimos cuenta casi de inmediato que no escalaba los gráficos grandes que recibía de los datos reales. Pasamos de SVG a Canvas y trabajamos un poco en WebGL. Al final, lo que mejor funcionó fue Canvas. Victor Fernandes fue el mago que usó estrategias creativas e ingeniosas para sacar el máximo de su rendimiento para nuestras necesidades (eso es un tema para otra publicación en el blog). Luego de generar gráficos cada vez más grandes, llegamos a la conclusión de que el cuello de botella ya no era el rendimiento del navegador, era la legibilidad del gráfico para el usuario. Podíamos graficar 30 000 nodos y 100 000 líneas, pero ¿por qué alguien querría hacer eso?
Como saben muchos de los profesionales de la visualización de datos, los diagramas de red son un ámbito delicado. Aunque parecen perfectos para comprender relaciones, pueden salirse de control muy rápido si hablamos de gráficos grandes y con muchas conexiones, algo que solemos llamar «el problema de la bola de pelos».
Nunca fue realista pensar que podríamos ver la red completa en el navegador. Por lo general, el analista de fraude solo ve un subgráfico generado a partir de los datos de un evento alertado actual y el contexto histórico pertinente y, luego, puede expandir los nodos para descubrir otras conexiones. Los investigadores comienzan con una consulta más general (p. ej., «todos los fraudes que se pasaron por alto la semana pasada»), ven el gráfico generado a partir de todos los eventos e intentan identificar nuevos patrones interesantes. En ambos casos, estamos utilizando un enfoque de «buscar y ampliar a pedido» en lugar del paradigma de visualización de datos clásico de «primero sintetizar, acercar y filtrar, luego los detalles a pedido».
Esto significa que, por lo general, podemos evitar esos grandes gráficos, pero, a veces, tenemos que hacerles frente. Si bien no se pueden interpretar, pueden ser bastante bonitos, por lo que los llamamos «Arte de datos de Genoma». Sirven para usar como fondos de pantalla o en remeras y, quizás, puedan formar parte de una exhibición de arte de datos algún día:

Fraude de relato
A medida que fuimos aprendiendo más sobre el fraude conectado, resultó evidente que había una dimensión fundamental de algunos de estos patrones que no estábamos codificando de forma visual: el tiempo. El aspecto temporal de un ataque de fraude es sumamente importante: la frecuencia y la periodicidad de los eventos son indicadores importantes de las actividades fraudulentas.
Debido a esto, pasamos a desarrollar un histograma temporal para Genoma. El histograma muestra la distribución a lo largo del tiempo de los eventos que generan el gráfico. Si bien parece algo sencillo de hacer, presenta algunos desafíos, tal y como suele suceder al desarrollar visualizaciones de datos para algún producto. Luís Cardoso redactó una publicación para el blog sobre eso, vale la pena leerla.
El histograma permite binning, desplazamientos y ampliaciones ajustables e incluso tiene un gráfico general subdividido en franjas. Todo esto solucionó muchos de nuestros problemas. Sin embargo, todavía queríamos relacionar el diagrama de red con el histograma y, para ello, utilizamos otro canal visual: la animación. Al animar el histograma temporal, vemos como se desarrolla la historia a lo largo del tiempo a medida que aparecen nuevos nodos y nuevas conexiones en la pantalla.
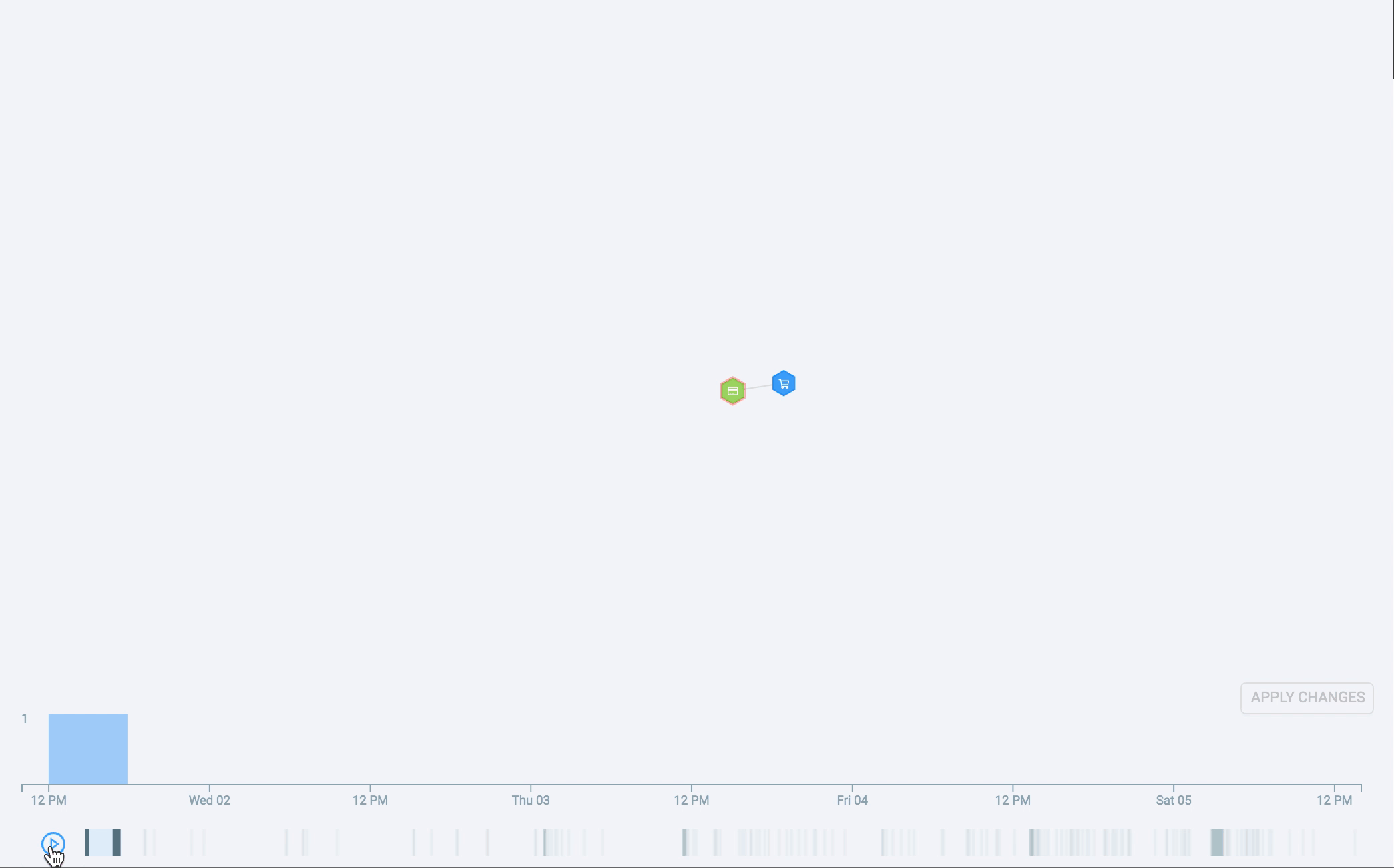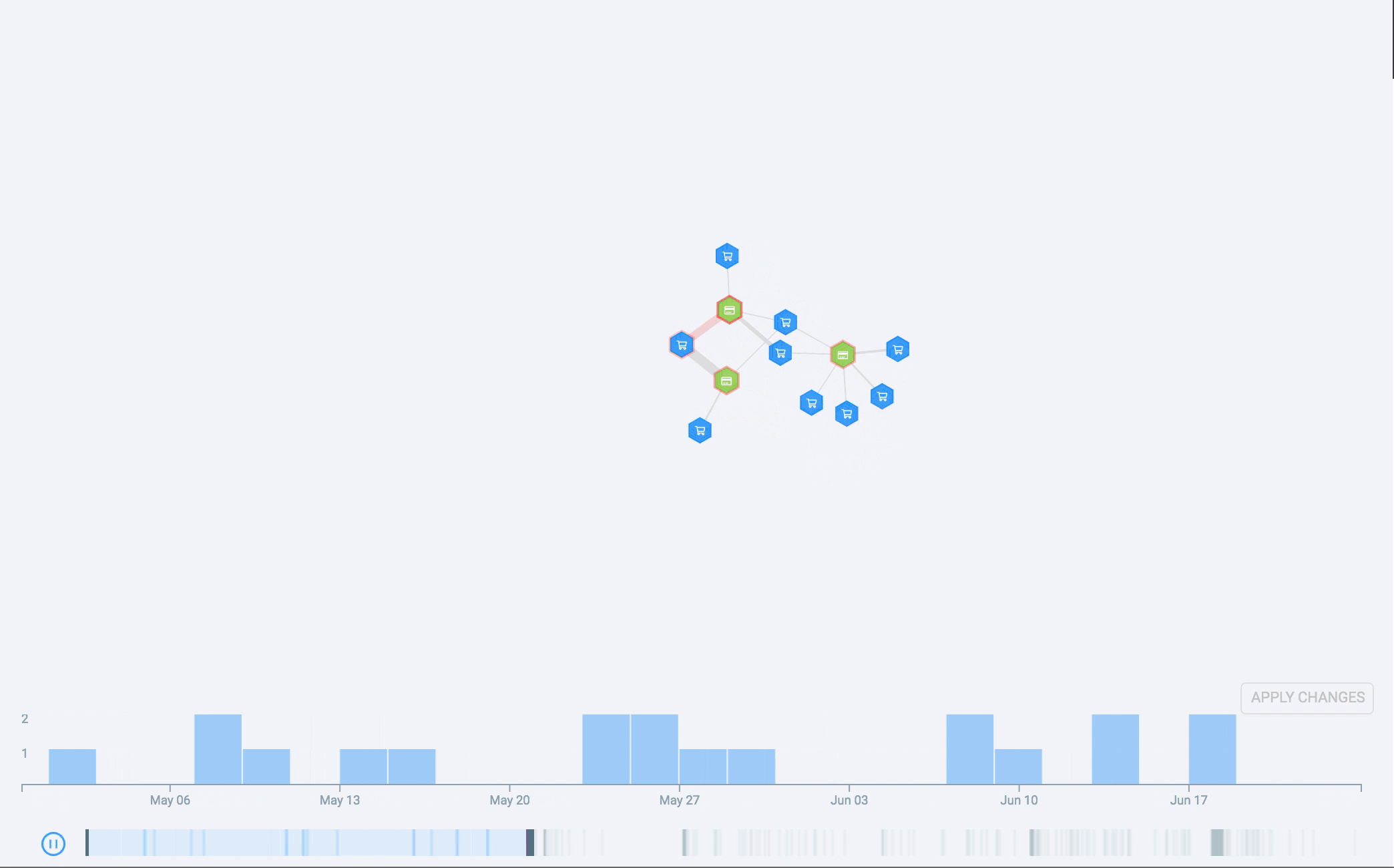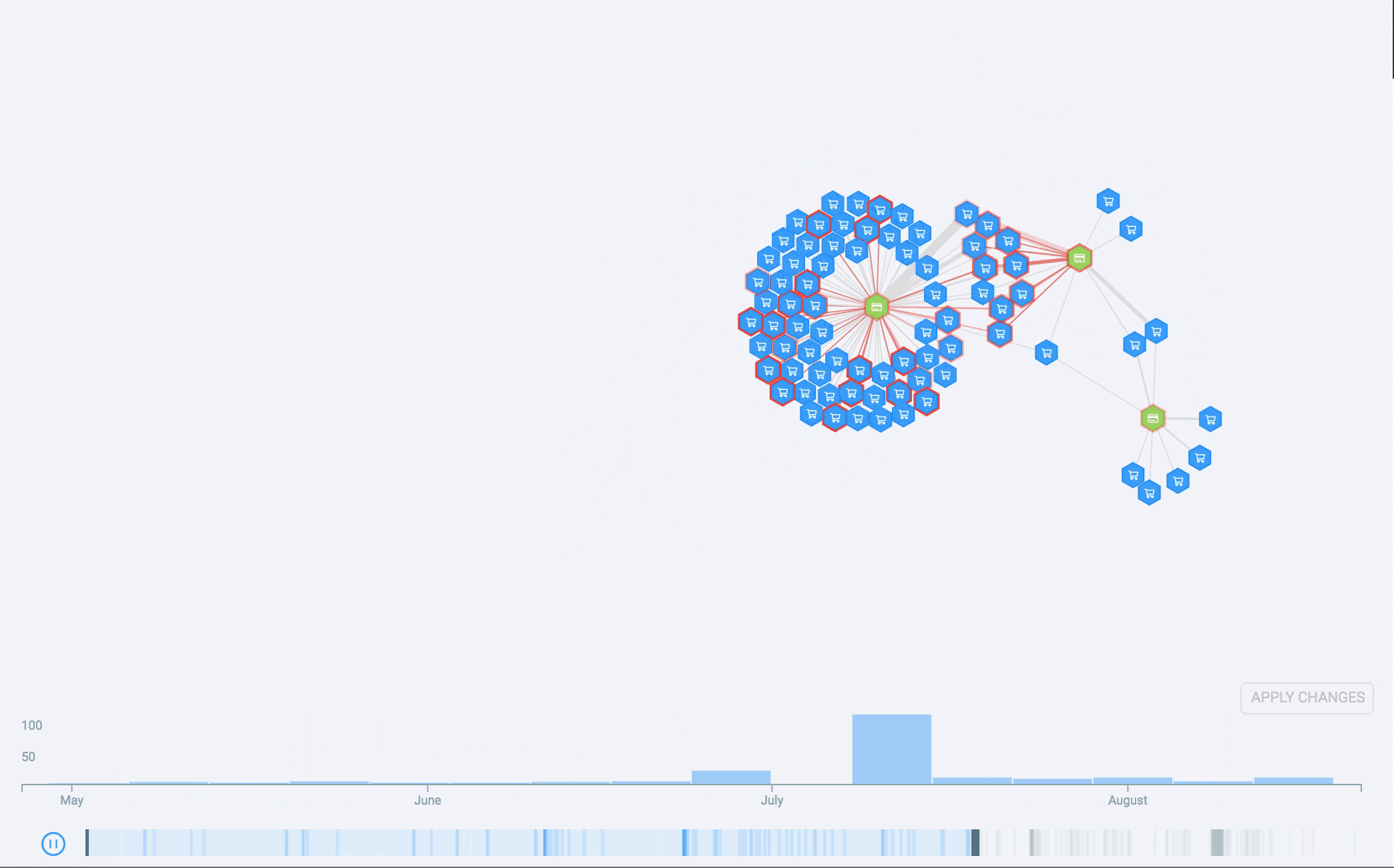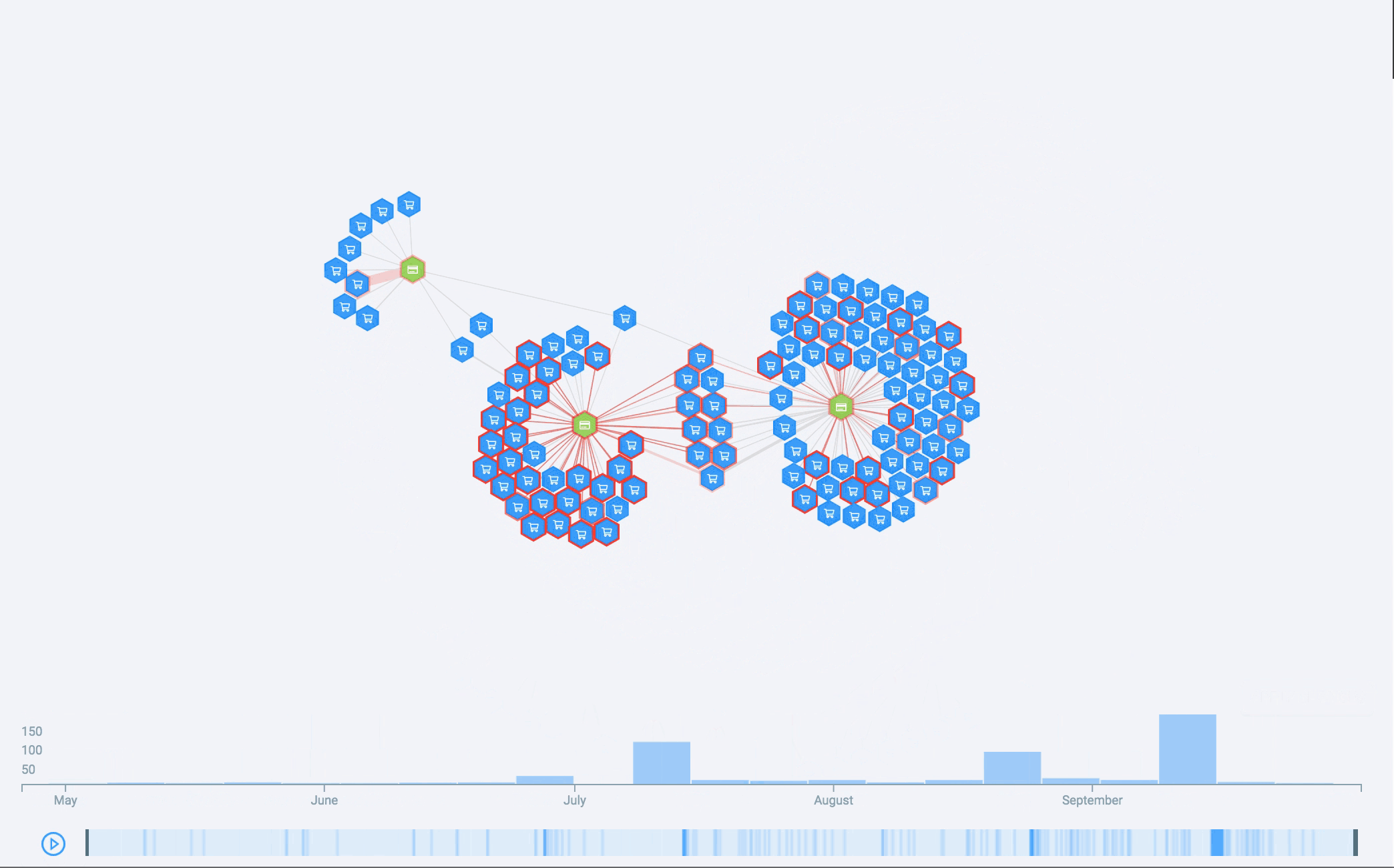
Qué nos depara el futuro
Genoma ya les brinda perspectivas a los analistas sobre cómo se ve el fraude. Ahora le pregunta es: «¿Cómo podemos mejorarlo aún más?». ¿Cómo podemos hacer para que el gráfico sea todavía más fácil de leer e interpretar?
Nuestro próximo objetivo es crear el acondicionador perfecto para llevar a Genoma a otro nivel para que podamos desenmarañar las complicadas «bolas de pelo», los gráficos grandes y con muchas conexiones. Es decir, estamos preparando la mezcla adecuada de «ingredientes» (estructuras alternativas, agrupación de lineas, agrupación de nodos o integración de gráficos) para crear un modo de vista general escalable que complemente la vista de investigación.
También estamos tratando de descubrir cómo incorporar la dimensión geoespacial. Al igual que el tiempo, es una señal de algunos modus operandi fraudulentos. Estamos ansiosos por explorar ese lado de la GeoViz.
El aprendizaje automático siempre es el centro
Por último, la IA siempre es el centro en Feedzai y nuestros científicos de datos trabajan duro para hacer que Genoma sea cada vez más inteligente a fin de que pueda asistir de la mejor manera a los analistas de fraude en sus investigaciones. El equipo ya ha progresado mucho en este frente, incluso al calificar subgráficos para recomendar áreas interesantes del gráfico y al agrupar subgráficos que son todos ejemplos del mismo patrón de fraude (conocido como Genometrías). Se trata de hacer que el aprendizaje automático se pueda interpretar y procesar para mejorar la experiencia de los analistas con Genoma.
Sin embargo, todavía queda mucho por hacer, los científicos de datos de Feedzai tienen muchísimas ideas innovadoras que les gustaría explorar y experimentos de última generación que les gustaría llevar a cabo. Lo que empezó como un prototipo de dos días en una hackathon creció y evolucionó. Descubrimos nuestra base y creamos cimientos sólidos para seguir construyendo esta plataforma de visualización de datos de futura generación. Ahora la diversión continúa, ya que hay un mundo de posibilidades para la visualización de redes al alcance de nuestros dedos.